Using Semantic Model Refresh Templates & Fabric Data Pipelines for Scalable Model Maintenance
- Jihwan Kim
- Sep 21, 2025
- 3 min read
Why I Started Looking at Refresh Templates
For years, I’ve learned and worked with refresh schedules in Power BI. At a small scale, scheduled refresh is fine. But once the number of semantic models grows—or when multiple teams depend on a single model—the cracks start to show. I’ve had refresh failures in the middle of the night, dashboards showing stale data in critical meetings, and models that finished refreshing before upstream data was even ready.
When Microsoft introduced Semantic Model Refresh Templates (currently in preview), I decided to try them out in Fabric. What I discovered is that combining these templates with Data Pipelines changes the way I handle refresh. It’s no longer a background job—it becomes an orchestrated, governed process. That shift has made a difference in my projects, and I want to share what I’ve learned.
What I Learned About Refresh Templates
A semantic model refresh template is a pre-built activity I can drop into a pipeline. At first glance, it feels like a minor convenience. But here’s what stood out to me:
I can parameterize the dataset, workspace, and even control partial refresh.
Refresh is no longer isolated; it’s part of the same pipeline that runs my notebooks or dataflows.
Monitoring and logs for refresh sit right alongside the rest of the data pipeline.
A Scenario I Tried: Multi-Source Model
One of my test cases was a finance semantic model that combines Products, Customers, and Sales data. In the past, this model gave me headaches:
Products data sometimes wasn’t ready when the refresh kicked in.
Customers data flowed in only weekly, but the model tried to refresh daily anyway.
When refresh failed, there was no easy way to tie it back to the upstream pipeline that loaded Products or Customers.
With a refresh template, I re-built the process inside a Fabric pipeline:
Products and Customers data were transformed through dataflow-products and dataflow-customers.
Sales data and Date dimension are loaded from Lakehouse.
The semantic model refresh triggered only after all upstream tasks completed, using the “refresh after dataflow” template.
Finally, a Teams notification activity alerted stakeholders when the process finished—or failed.
Pipeline diagram:

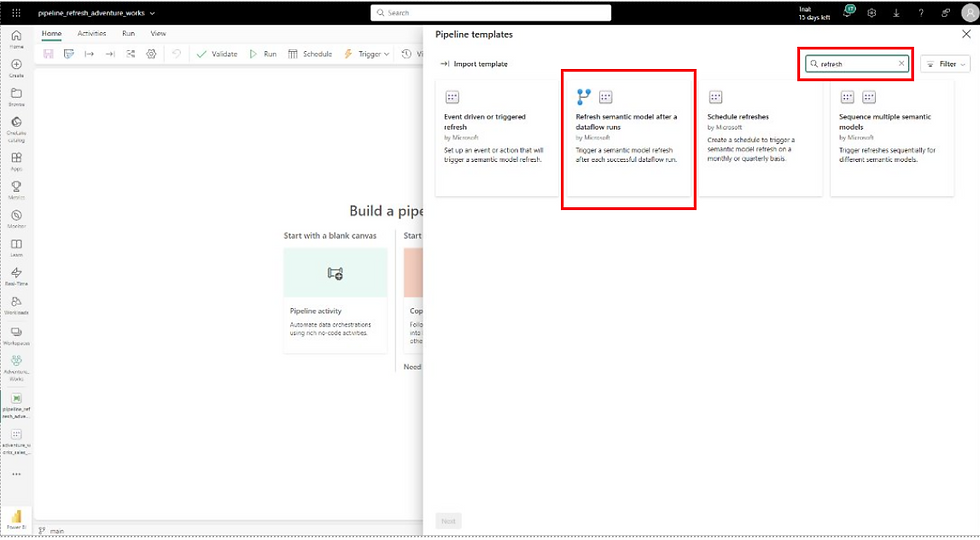
This made the entire flow more predictable. The semantic model refresh didn’t even start until everything upstream was ready. If something failed in one of dataflows, the model never refreshed against incomplete data.
How I Set It Up
Here’s the exact pattern I tested:
Created a new pipeline in Fabric.
Added a dataflow activity to clean Products and Customers data.
Dropped in the refresh template activity and pointed it at the semantic model.
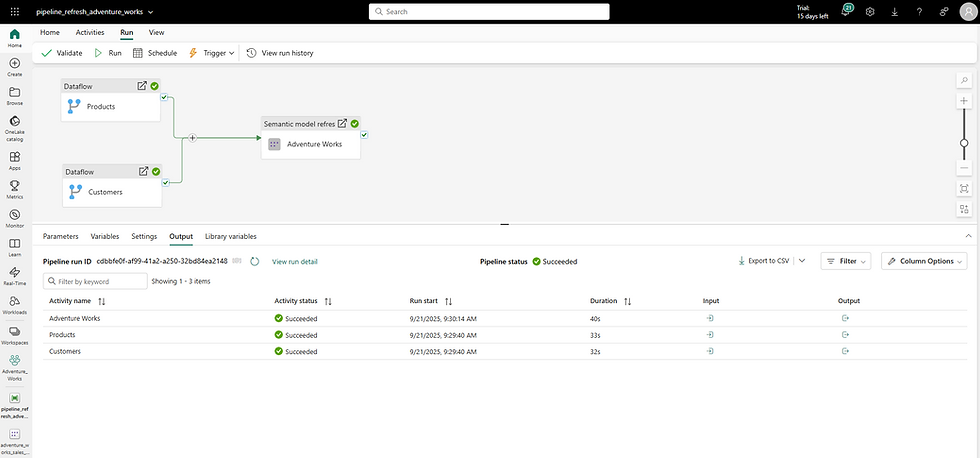
Example screenshot:

Lineage view:

It was surprisingly simple, but the impact was big: refresh became part of the whole process, not an afterthought.
Patterns I Discovered at Scale
The more I experimented, the more I realized the potential for enterprise setups:
I could chain models in sequence using templates like “sequence multiple semantic models”.
Independent models could refresh in parallel to save time.
Partial refresh let me cut down on refresh times by targeting only the partitions that changed (incremental refresh documentation).
Event-driven refresh allowed me to trigger a refresh the moment upstream work completed.
Pitfalls and Limitations I Noticed
While I found the feature powerful, a few things stood out to me during testing:
Pipeline governance: Just because you can run refresh in a pipeline doesn’t mean you should run every refresh there. For small, independent datasets, scheduled refresh might still be simpler.
Error handling: Pipelines provide logs, but the granularity of refresh error messages is sometimes limited. For deep troubleshooting, you may still need to check the semantic model refresh history directly.
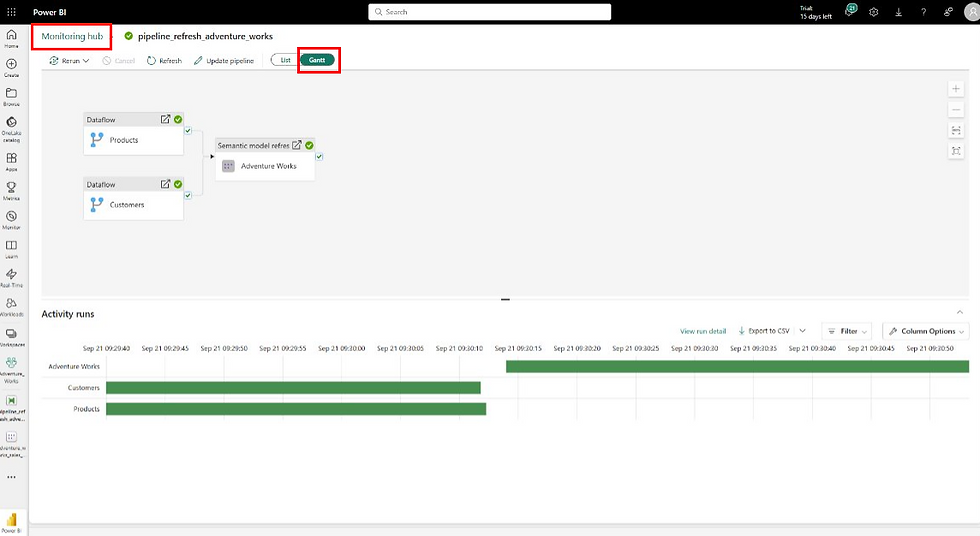
Monitoring, Alerting, and Governance – What Surprised Me
But still, the governance angle was bigger than I expected. With pipelines:
I had a single log of the entire refresh chain.
Alerts were much easier to set up—I routed pipeline status to Teams.
Refresh history lived alongside my upstream runs, making troubleshooting straightforward.
Costs became more transparent: I could see exactly how often refreshes ran and what they consumed.
Summary
Semantic Model Refresh Templates sound like a small feature, but they unlock a new way of thinking about refresh: not as a scheduled background job, but as part of a governed, orchestrated process.
When combined with Data Pipelines, they solve the dependency and monitoring problems I’ve hit so many times in the past. In enterprise settings, this approach makes refresh predictable, governed, and scalable.
If you’ve been burned by fragile refresh schedules, I’d encourage you to try this out. It’s been one of the most useful Fabric features I’ve tested recently.
I hope this gives fun and ideas to explore and experiment more with Data Pipelines in Fabric—I’ve found the learning process both challenging and rewarding, and I think you will too.



Comments